WiscKey: Separating Keys from Values in SSD-Conscious Storage
FAST ’16
https://dl.acm.org/doi/10.1145/3033273
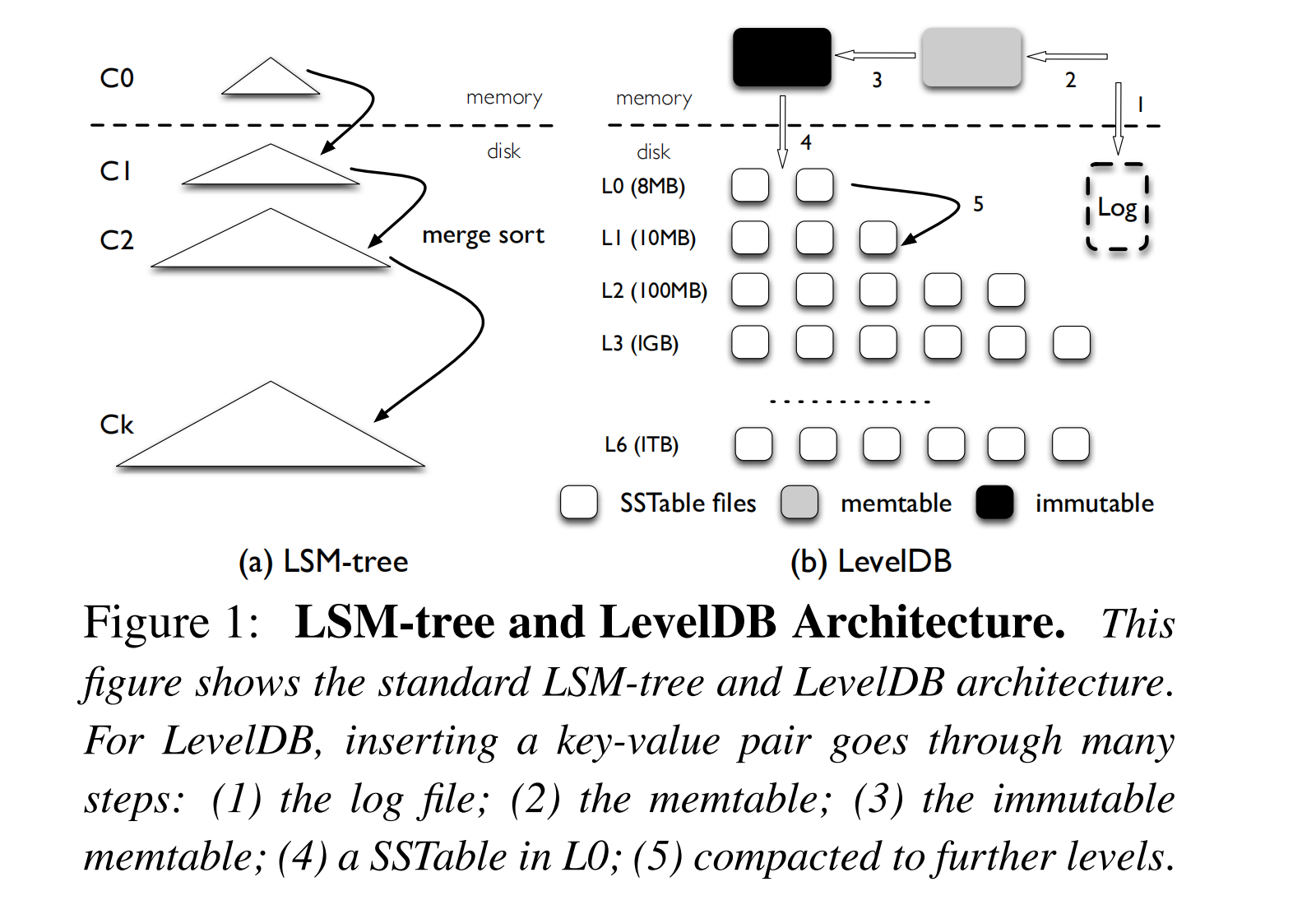
I/O 放大是 LSM-tree 固有的特性之一。新写入的数据被追加到 WAL 日志并写入内存 memtable,这种操作避免了对已有数据的读取和修改,因而非常高效。当内存中的结构达到一定大小或达到一定时间间隔时,LSM-tree 会将这些数据批量写入到磁盘上的持久化存储结构中(SSTable),低层文件通过 compaction 生成更高层的文件。
To maintain the size limit, once the total size of a level Li exceeds its limit, the compaction thread will choose one file from Li, merge sort with all the overlapped files of Li+1, and generate new Li+1 SSTable files.
写放大(Write Amplification)
由于 Li 的大小限制是 Li-1 的 10 倍,因此 Li-1 层的文件合并到 Li 时,最坏情况下可能会读取 Li 中的 10 个文件,并在排序后将这些文件写回 Li,因此,将一个文件从一个层级移动到另一个层级的写放大系数最高可达到 10 倍。
For a large dataset, since any newly generated table file can eventually migrate from L0 to L6 through a series of compaction steps, write amplification can be over 50 (10 for each gap between L1 to L6).
读放大(Read Amplification)
读放大的源头有两点:
- 首先,为了查找一个键值对 LevelDB 可能需要检查多个层级(L0 8个 + L1~L6 各一个 = 14)
- 其次,为了在一个 SSTable 文件中找到一个键值对,LevelDB 需要读取文件中的多个元数据块(index block + bloom-filter blocks)
假设查询一个不存在的 key,且 bloom-filter 过滤的结果是 false positive,对于查询 1KB 键值对的操作,需要读取一个 SSTable 的数据量为: 16-KB index block + 4-KB bloom-filter block + 4-KB data block = 24K。
Considering the 14 SSTable files in the worst case, the read amplification of LevelDB is 24 × 14 = 336. Smaller key-value pairs will lead to an even higher read amplification.
对于 HDD 盘,假设随机写延迟/顺序写延迟=1000,那么 LSM-tree 在写放大小于 1000 的情况下仍会比 B-Tree 快。这也是 LSM-tree 在传统 HDD 盘取得成功的重要原因。
SSD(固态硬盘)则有所不同,在设计键值存储系统时需要考虑三个重要的因素:
- First, the difference between random and sequential performance is not nearly as large as with HDDs
- Second, SSDs have a large degree of internal parallelism
- Third, SSDs can wear out through repeated writes; the high write amplification in LSM-trees can significantly reduce device lifetime
WiscKey
The central idea behind WiscKey is the separation of keys and values; only keys are kept sorted in the LSM-tree, while values are stored separately in a log.
WiscKey 包含四个关键的设计要点:
- First, WiscKey separates keys from values, keeping only keys in the LSM-tree and the values in a separate log file
- Second, to deal with unsorted values (which necessitate random access during range queries), WiscKey uses the parallel random-read characteristic of SSD devices
- Third, WiscKey utilizes unique crash-consistency and garbage-collection techniques to efficiently manage the value log
- Finally, WiscKey optimizes performance by removing the LSM-tree log without sacrificing consistency, thus reducing system-call overhead from small writes
一个很直观的感觉,LSM-tree 只保存 key 和 value 的位置(<vLog-offset, value-size>),在 value 很大的情况下,能避免对 value 进行 compaction,进而减少了写放大,节省了带宽,增加了 SSD 的使用周期。同时,LSM-tree 占用的存储也更少了,能更充分利用缓存和较少的层级减少读放大。
Readers might assume that WiscKey will be slower than LevelDB for lookups, due to its extra I/O to retrieve the value.
However, since the LSM-tree of WiscKey is much smaller than LevelDB (for the same database size), a lookup may search fewer levels of table files in the LSM-tree and a significant portion of the LSM-tree can be easily cached in memory.
当然 k/v 分离也带来了一些挑战,最直观的挑战是当写入随机的键值对,然后进行 Range Query,导致查询到的 value 分布在 log file 的不同位置,文章提出用并发读来提高带宽。作者对其它挑战( Garbage Collection & )也都提出了相应的解决方案,感兴趣的读者请阅读论文。
Further readings
- HashKV: Enabling Efficient Updates in KV Storage via Hashing, 2018. Section 2.2 对 WiscKey 的介绍值得一读