DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node
https://dl.acm.org/doi/abs/10.5555/3454287.3455520
Current state-of-the-art approximate nearest neighbor search (ANNS) algorithms generate indices that must be stored in main memory for fast high-recall search. This makes them expensive and limits the size of the dataset.
对于较大的数据集,可以通过 PQ 将数据进行压缩或将数据集分片到多个节点,但两种方式都有不足,PQ 会降低召回率,而 sharding 需要更多的硬件资源:
- their 1-recall@1 is rather low (around 0.5) since the data compression is lossy.
- extending this to web scale data with hundreds of billions of points would require thousands of machines.
DiskANN
DiskANN, an SSD-resident ANNS system based on our new graph-based indexing algorithm called Vamana.
Vamana 生成的图索引相对 HNSW 或 NSG 具有更小的直径(diameter),从而最小化磁盘读 I/O。另外:
- Vamana 生成的图索引也可直接在内存中使用,其搜索性能可以媲美或超越 HNSW 或 NSG 等内存图索引算法
- Vamana 可以将数据集的多个分区分别生成的索引 merge 成一个索引,其搜索性能几乎与为整个数据集构建的单个索引相同,这对小内存环境非常友好
- Vamana 可以与 PQ 结合使用,将压缩过的数据存储在内存中来加速搜索过程中的距离计算
Vamana Graph Construction Algorithm
HNSW,NSG 和 Vamana 本质上都是图算法,都可以抽象为两个操作 GreedySearch 和 RobustPrune:

所不同的是:
- HNSW 和 NSG 没有可以调整的参数 α,隐式地使用 α = 1,而这正是 Vamana 能够在 graph degree 和 diameter 上进行 trade-off 的关键
- 另外,Vamana 和 NSG 使用 GreedySearch(s, p, 1, L) 活动的所有点的集合作为 RobustPrune 的候选集,以此来给图增加 long-range edged,而 HNSW 则是通过分层来达到此效果
- NSG 的初始图是一个数据集近似的 K-nearest neighbor graph,耗时相对较长且消耗更多内存,而 HNSW 和 Vamana 的初始图则相对简单,前者以空图开始,后者以随机图开始
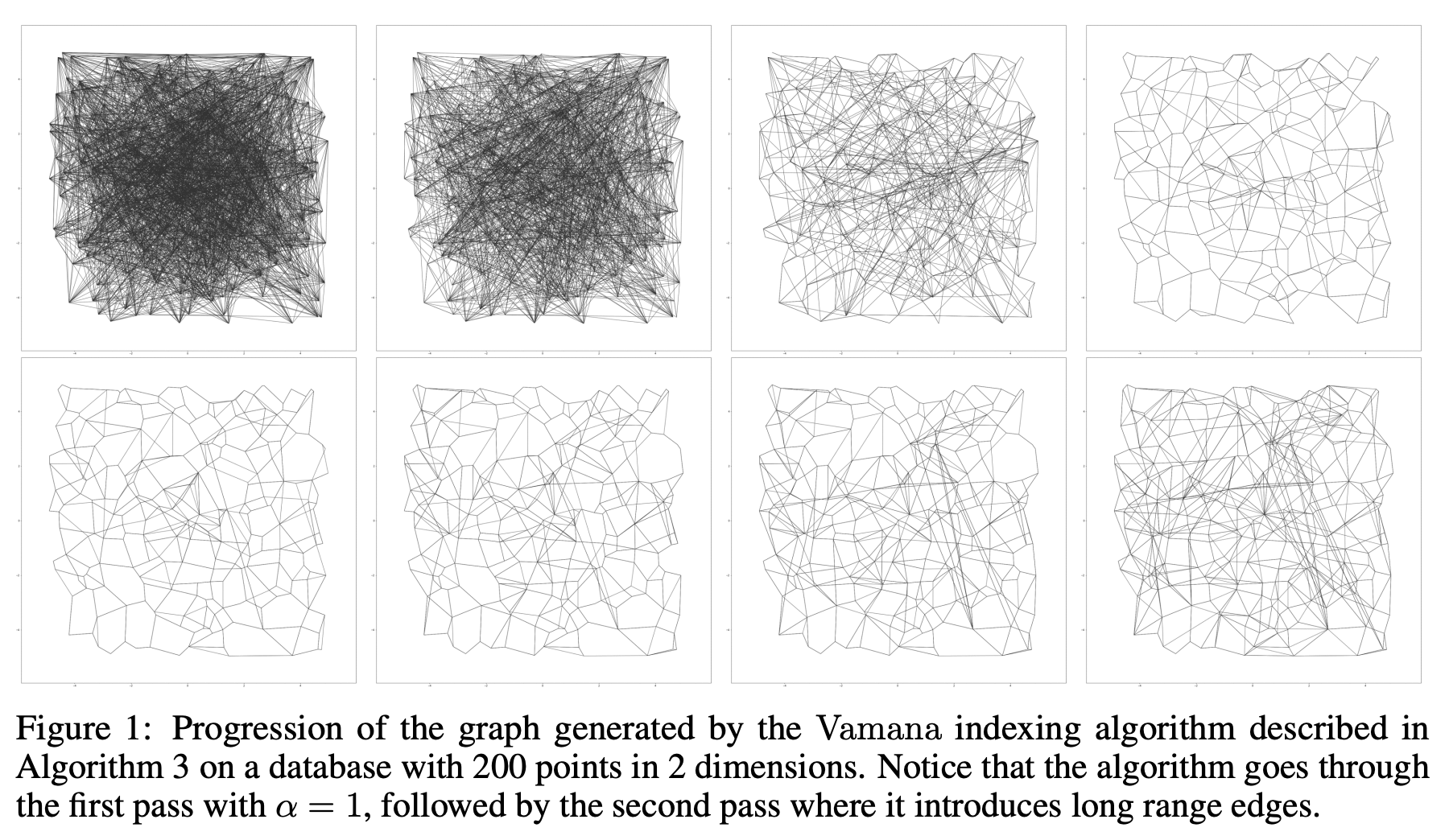
- Vamana 需要扫两边数据集,第二遍能够提高图的质量

从下图可以看出,第一行使用 α = 1 消除了很多不必要的边,第二行使用 α > 1 将一些所谓的 long-range edges 加回到图中:
DiskANN 通过 BeamSearch(设置 beamwidth 一次读多个数据块) 和缓存最常访问的节点(eg. by caching all vertices that are C = 3 or 4 hops from the starting point s)来加速查询。 另外,DiskANN 将邻居节点的向量保存在磁盘索引文件中,来提高搜索的精度(Implicit Re-Ranking Using Full-Precision Vectors)。
Code
- microsoft/DiskANN, Graph-structured Indices for Scalable, Fast, Fresh and Filtered Approximate Nearest Neighbor Search
Further readings
- FreshDiskANN: A Fast and Accurate Graph-Based ANN Index for Streaming Similarity Search, 2021
- OOD-DiskANN: Efficient and Scalable Graph ANNS for Out-of-Distribution Queries, 2022
- Filtered−DiskANN: Graph Algorithms for Approximate Nearest Neighbor Search with Filters, 2023