Revisiting the Inverted Indices for Billion-Scale Approximate Nearest Neighbors
https://arxiv.org/abs/1802.02422
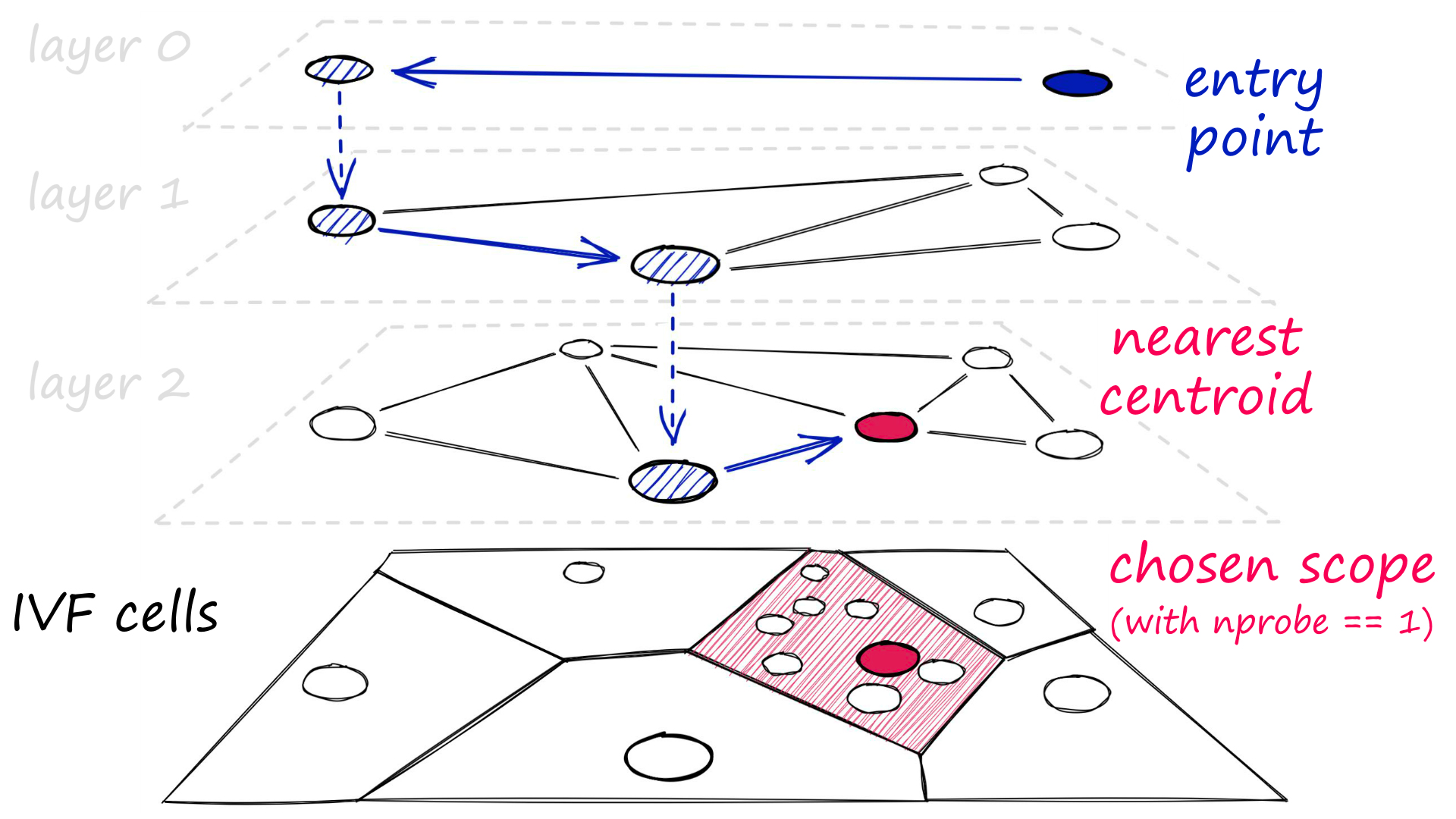
IVF 在较大码本(codebook, K > 2^17)的情况下具有更好的搜索效果,但查找相近 Centroid 会相对比较费时。
The only practical reason, preventing their usage, is the expensive procedure of query assignment that takes O(K) operations.
使用 HNSW 对 Centroid set 构建一个索引能够获得不错的效果(之前有研究用 kd-tree 来查找最近 centroids 效果并不理想)。
HNSW allows obtaining a small top of the closest centroids with almost perfect accuracy in a submillisecond time.
文中提到的 Grouping and pruning 能够对子分区更好地划分以提高查询精度,可用于大数据的数据压缩。